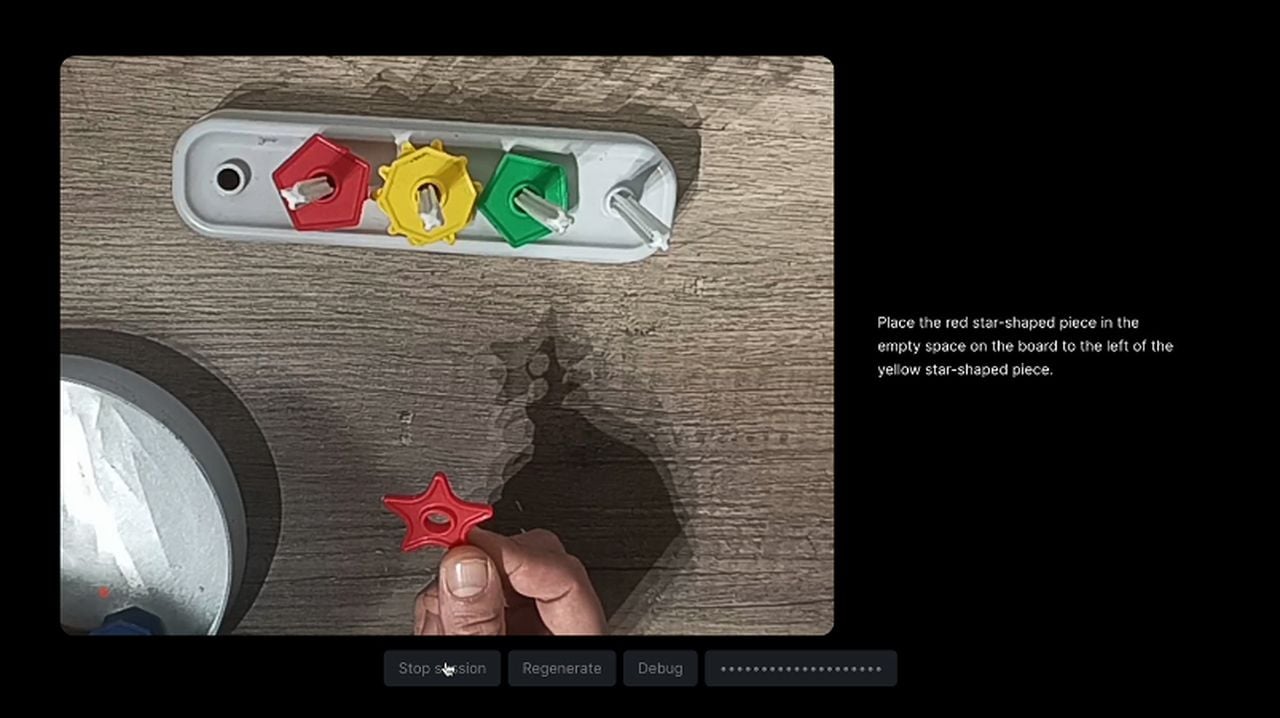
Si, comme moi, vous avez été un peu déçu d’apprendre que la démonstration de Google Gemini, publiée au début du mois, relevait plus de l’édition astucieuse que de l’avancée technologique. Vous serez heureux d’apprendre que nous n’aurons peut-être pas à attendre trop longtemps avant que quelque chose de similaire soit disponible.
Après avoir vu la démonstration de Google Gemini et la révélation de l’article de blog dévoilant ses secrets. Julien De Luca s’est demandé si l’expérience Gemini présentée par Google pouvait être plus qu’une simple démonstration scénarisée. Il a ensuite créé une expérience amusante pour explorer la faisabilité d’interactions IA en temps réel similaires à celles présentées dans la démonstration Gemini. Voici quelques restrictions qu’il a imposées au projet pour qu’il reste conforme à la démonstration originale de Google.
- Le projet doit se dérouler en temps réel
- L’utilisateur doit pouvoir diffuser une vidéo
- L’utilisateur doit pouvoir parler à l’assistant sans interagir avec l’interface utilisateur.
- L’assistant doit utiliser les données vidéo pour répondre aux questions de l’utilisateur.
- L’assistant doit répondre en parlant.
En raison de la capacité actuelle de Chat GPT Vision à n’accepter que des images individuelles, De Luca a dû télécharger une série d’images et de captures d’écran extraites de la vidéo à intervalles réguliers pour que le GPT comprenne ce qui se passait .
« KABOOM ! Nous avons maintenant une seule image représentant un flux vidéo. Maintenant, nous parlons. J’ai dû peaufiner l’invite du système pour lui faire « comprendre » qu’il s’agissait d’une vidéo. Sinon, il ne cessait de mentionner des « motifs », des « bandes » ou des « grilles ». J’ai également insisté sur la temporalité des images, afin qu’il raisonne en utilisant la séquence d’images. Ce système pourrait certainement être amélioré, mais pour cette expérience, il fonctionne suffisamment bien », explique M. De Luca. Pour en savoir plus sur ce processus, rendez-vous sur le site web de Crafters.ai ou sur GitHub.
Création d’une véritable démo Google Gemini
AI Jason a également créé un exemple combinant les technologies GPT-4, Whisper et Text-to-Speech (TTS). Regardez la vidéo ci-dessous pour une démonstration et pour en savoir plus sur la façon de créer un exemple vous-même en utilisant différentes technologies d’IA combinées ensemble.
Pour créer une démo qui émule le Gemini original avec l’intégration de GPT-4V, Whisper et TTS, les développeurs s’embarquent dans un voyage technique complexe. Ce processus commence par la mise en place d’un projet Next.js, qui sert de base à l’intégration de fonctionnalités telles que l’enregistrement vidéo, la transcription audio et la génération de grilles d’images. La mise en œuvre d’appels API vers OpenAI est cruciale, car elle permet à l’IA d’engager une conversation avec les utilisateurs, de répondre à leurs questions et de fournir des réponses en temps réel.
La conception de l’expérience utilisateur est au cœur de la démo, l’accent étant mis sur la création d’une interface intuitive qui facilite les interactions naturelles avec l’IA, comme s’il s’agissait d’une conversation avec un autre être humain. Il s’agit notamment de la capacité de l’IA à comprendre les signaux visuels et à y répondre de manière appropriée.
La reconstruction de la démo Gemini avec GPT-4V, Whisper et Text-To-Speech est une indication claire des progrès réalisés vers un avenir où l’IA pourra nous comprendre et interagir avec nous par l’intermédiaire de plusieurs sens. Cette évolution promet d’offrir une expérience plus naturelle et immersive. Les contributions et les idées continues de la communauté de l’IA seront cruciales pour façonner l’avenir des applications multimodales.
Crédit photo : Julien De Luca
Lire plus Guide:
- Google Gemini sur Android en action
- Le nouveau modèle linguistique Gemini de Google est impressionnant
- Démarrer avec Google Gemini sur votre iPhone
- Utiliser l’API Gemini Pro pour créer des applications d’IA dans Google AI Studio
- Samsung Galaxy et Google Cloud s’associent pour l’IA
- Comment utiliser Google Gemini sur votre téléphone Android ?



