Если вы, как и я, были немного разочарованы, узнав, что демо-версия Google Gemini, опубликованная ранее в этом месяце, была скорее умным изменением, чем технологическим достижением. Вы будете рады узнать, что нам, возможно, не придется слишком долго ждать, прежде чем появится что-то подобное.
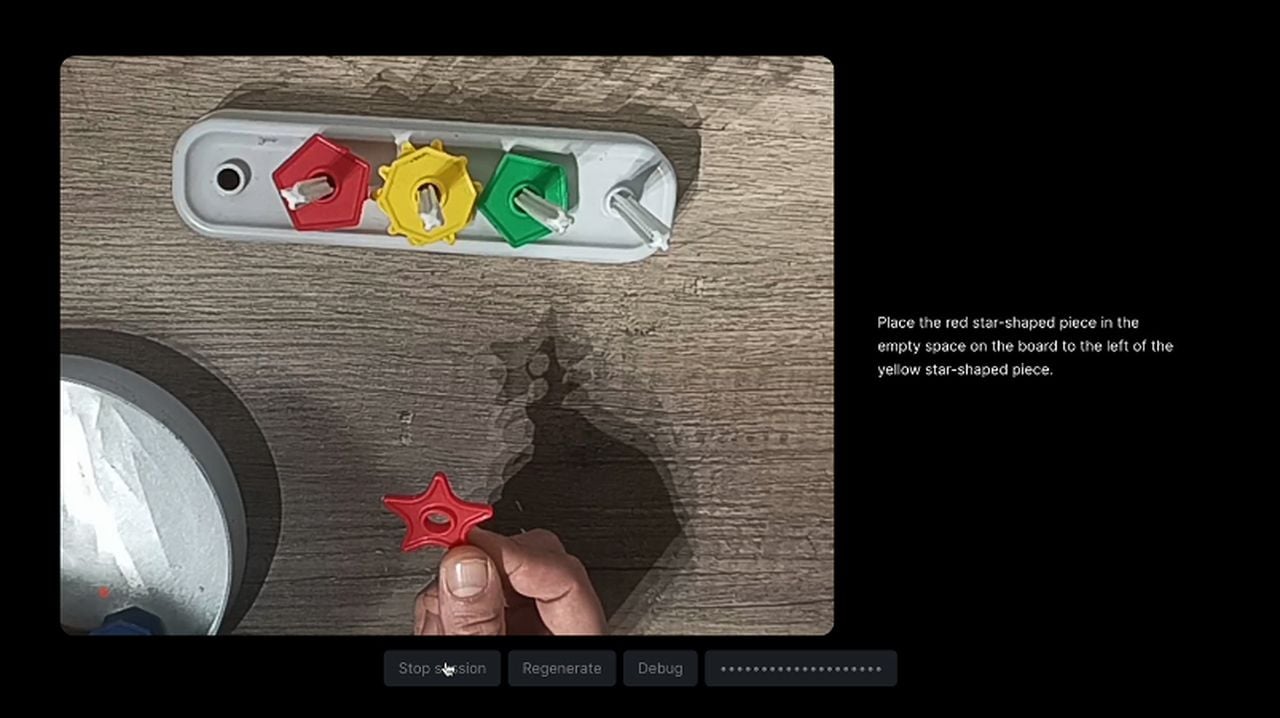
Увидев демонстрацию Google Gemini и раскрытие статьи в блоге, раскрывающей его секреты. Жюльен Де Лука задал себе вопрос если бы эксперимент Gemini, представленный Google, мог быть чем-то большим, чем простая демонстрация по сценарию. Затем он провел забавный эксперимент, чтобы изучить возможность взаимодействия ИИ в реальном времени, аналогичного тем, которые были показаны в демо-версии Gemini. Вот некоторые ограничения, которые он наложил на проект, чтобы он соответствовал оригинальной демо-версии Google.
- Проект должен происходить в режиме реального времени
- Пользователь должен иметь возможность транслировать видео
- Пользователь должен иметь возможность разговаривать с помощником, не взаимодействуя с пользовательским интерфейсом.
- Помощник должен использовать видеоданные для ответа на вопросы пользователя.
- Ассистент должен ответить, заговорив.
В связи с тем, что Chat GPT Vision в настоящее время может принимать только отдельные изображения, Де Луке приходилось через определенные промежутки времени загружать серию изображений и скриншотов из видео, чтобы GPT могла понять, что происходит. .
«КАБУМ! Теперь у нас есть одно изображение, представляющее видеопоток. Сейчас мы говорим. Мне пришлось настроить системную подсказку, чтобы она «поняла», что это видео. В противном случае он продолжал упоминать «узоры», «полоски» или «сетки». Я также настаивал на временности изображений, чтобы он рассуждал, используя последовательность изображений. Эту систему определенно можно улучшить, но для данного опыта она работает достаточно хорошо»., - объясняет г-н Де Лука. Чтобы узнать больше об этом процессе, посетите сайт Crafters.ai или GitHub.
Создание настоящей демо-версии Google Gemini
AI Джейсон также создал пример, сочетающий технологии GPT-4, Whisper и Text-to-Speech (TTS). Посмотрите видео ниже, чтобы увидеть демонстрацию и узнать больше о том, как создать пример самостоятельно, используя различные технологии искусственного интеллекта в сочетании друг с другом.
Чтобы создать демо-версию, имитирующую оригинальный Gemini с интеграцией GPT-4V, Whisper и TTS, разработчики отправляются в сложный технический путь. Этот процесс начинается с настройки проекта Next.js, который служит основой для интеграции таких функций, как запись видео, транскрипция звука и создание сетки изображений. Внедрение API-вызовов OpenAI имеет решающее значение, поскольку позволяет ИИ общаться с пользователями, отвечать на их вопросы и предоставлять ответы в режиме реального времени.
В основе демонстрации лежит дизайн пользовательского опыта с упором на создание интуитивно понятного интерфейса, который облегчает естественное взаимодействие с ИИ, как если бы это был разговор с другим человеком. К ним относится способность ИИ понимать визуальные сигналы и соответствующим образом реагировать на них.
Перестройка демо-версии Gemini с использованием GPT-4V, Whisper и Text-To-Speech является четким показателем прогресса на пути к будущему, в котором ИИ сможет понимать нас и взаимодействовать с нами посредством нескольких чувств. Эта разработка обещает предложить более естественный и захватывающий опыт. Постоянный вклад и идеи сообщества искусственного интеллекта будут иметь решающее значение для формирования будущего мультимодальных приложений.
Фото предоставлено: Жюльен Де Лука
Читать далее Руководство:
- Google Gemini на Android в действии
- Начните работу с Google Gemini на своем iPhone
- Используйте Gemini Pro API для создания приложений искусственного интеллекта в Google AI Studio.
- Новая языковая модель Gemini от Google впечатляет
- Samsung Galaxy и Google Cloud объединяются для разработки искусственного интеллекта
- Как использовать Google Gemini на телефоне Android?


