Si, como yo, se sintió un poco decepcionado al saber que la demostración de Google Gemini, publicada a principios de este mes, fue más una edición inteligente que un avance tecnológico. Le alegrará saber que es posible que no tengamos que esperar demasiado antes de que algo similar esté disponible.
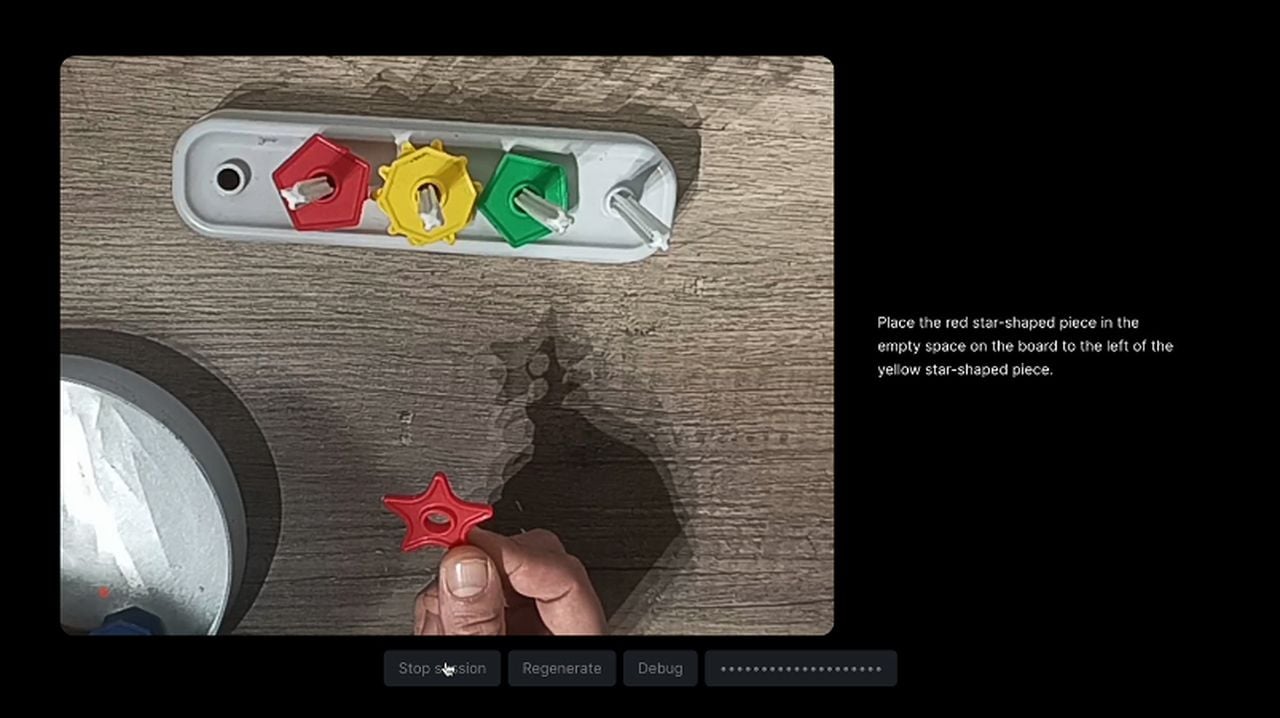
Después de ver la demostración de Google Gemini y la revelación del artículo del blog que revela sus secretos. se preguntó Julien De Luca si el experimento Gemini presentado por Google podría ser más que una simple demostración guionada. Luego creó un experimento divertido para explorar la viabilidad de interacciones de IA en tiempo real similares a las que se muestran en la demostración de Gemini. Aquí hay algunas restricciones que impuso al proyecto para mantenerlo consistente con la demostración original de Google.
- El proyecto debe desarrollarse en tiempo real.
- El usuario debe poder transmitir un vídeo.
- El usuario debería poder hablar con el asistente sin interactuar con la interfaz de usuario.
- El asistente debe utilizar los datos del vídeo para responder a las preguntas del usuario.
- El asistente debe responder hablando.
Debido a la capacidad actual de Chat GPT Vision de aceptar solo imágenes individuales, De Luca tuvo que subir una serie de imágenes y capturas de pantalla del vídeo a intervalos regulares para que el GPT entendiera lo que estaba pasando. .
“¡KABOOM! Ahora tenemos una única imagen que representa una transmisión de video. Ahora estamos hablando. Tuve que modificar el mensaje del sistema para que "entendiera" que era un video. De lo contrario, siguió mencionando "patrones", "tiras" o "cuadrículas". También insistí en la temporalidad de las imágenes, para que razone utilizando la secuencia de imágenes. Este sistema definitivamente podría mejorarse, pero para esta experiencia funciona bastante bien”, explica De Luca. Para obtener más información sobre este proceso, visite el sitio web Crafters.ai o GitHub.
Creando una demostración real de Google Gemini
AI Jason también creó un ejemplo que combina las tecnologías GPT-4, Whisper y Text-to-Speech (TTS). Mire el vídeo a continuación para ver una demostración y obtener más información sobre cómo crear un ejemplo usted mismo utilizando diferentes tecnologías de IA combinadas.
Para crear una demostración que emule el Gemini original con integración GPT-4V, Whisper y TTS, los desarrolladores se embarcan en un complejo viaje técnico. Este proceso comienza con la configuración de un proyecto Next.js, que sirve como base para integrar funciones como grabación de video, transcripción de audio y generación de cuadrículas de imágenes. La implementación de llamadas API a OpenAI es crucial porque permite que la IA entable una conversación con los usuarios, responda sus preguntas y brinde respuestas en tiempo real.
El diseño de la experiencia del usuario está en el centro de la demostración, centrándose en la creación de una interfaz intuitiva que facilite las interacciones naturales con la IA, como si fuera una conversación con otro ser humano. Estos incluyen la capacidad de la IA para comprender señales visuales y responder a ellas de manera adecuada.
Reconstruir la demostración de Gemini con GPT-4V, Whisper y Text-To-Speech es una clara indicación del progreso hacia un futuro en el que la IA pueda comprendernos e interactuar con nosotros a través de múltiples sentidos. Este desarrollo promete ofrecer una experiencia más natural e inmersiva. Las continuas contribuciones y conocimientos de la comunidad de IA serán cruciales para dar forma al futuro de las aplicaciones multimodales.
Crédito de la foto: Julien De Luca.
Leer más Guía:
- Google Gemini en Android en acción
- Comienza a utilizar Google Gemini en tu iPhone
- Utilice la API de Gemini Pro para crear aplicaciones de IA en Google AI Studio
- Samsung Galaxy y Google Cloud se unen para la IA
- ¿Cómo utilizar Google Gemini en tu teléfono Android?
- El nuevo modelo de lenguaje Gemini de Google es impresionante


